経営学部吉見憲二
テキストマイニングを用いた情報社会における諸課題へのアプローチ
ユーザーによる情報発信の増加とデータ利活用へのニーズ
インターネットやスマートフォン、ソーシャルメディアといった製品やサービスの普及によって、社会における「情報」の重要性はますます高まってきています。特に、一般的なユーザーからの情報発信が容易になったことにより、これまで社会に存在しなかったような大量のユーザーデータが蓄積されるようになりました。こうしたビッグデータの利活用は新しい観点からの研究を可能にしています。例えば、国立情報学研究所データセット共同利用研究開発センターが運営するデータセットの共同利用事業である情報学研究データリポジトリでは、さまざまな企業や組織が保有している大容量のデータセットが提供されており、自身の研究に活用することができます。
〈図1:情報学研究データリポジトリ〉
テキストマイニングを用いたYahoo! 知恵袋データの分析
私が行っている共同研究では、ヤフー株式会社が提供する「Yahoo! 知恵袋データ(第3版)」を分析対象とし、テキストマイニングを用いて新たな知見や意外な関係性を見出すことを試みています。テキストマイニングはテキストデータを対象としたデータマイニング手法であり、頻出語の抽出や語と語の共起関係の描写から有用な情報を取得することを目的に利用されています。
Q&Aコミュニティの投稿データはカテゴリ分けされていることから関係がない投稿のノイズが入りにくく、質問文の形式をとっていることからより投稿者の問題意識が強いという分析上の優位点があります。これまでの研究では、育児や国内旅行、スマートフォンといったカテゴリについて分析を行ってきました。特に、育児に関する投稿の分析では、月齢による質問傾向の変化やベストアンサーにおける頻出語といった観点から「育児の悩み」の可視化とそれに対する望ましい対応について検討しています。もちろん、こうした手法は製品レビューを対象にすることで、商品開発やマーケティング等にも応用することができるでしょう。

〈図2:「育児の悩み」の研究動機 〉
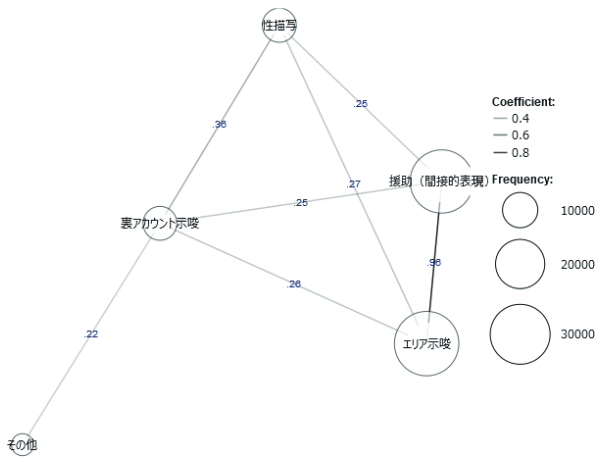
さらに、投稿データの分析は社会問題の解決にも貢献することが期待できます。以前に行ったTwitterの投稿データを対象とした分析では、売買春に関連した問題投稿のハッシュタグの傾向について明らかにし、ハッシュタグの共起関係から疑わしい投稿の検出手法を提案しました。同様の手法は自殺教唆等のハッシュタグに起因する別の社会問題にも適用することが可能です。
このようにテキストマイニングと投稿データや公開データを組み合わせることで、幅広い研究テーマを扱うことができます。しかしながら、ユーザーの利用傾向の変化やデータ提供元の方針転換等によってこれまでのアプローチが継続できなくなることもあります。そのため、現時点で利用できるデータを総動員して研究としての記録を残しておくことが重要であり、私自身の研究もそうした流れに位置づけられるものとなっています。
〈図3:売買春に関連した問題投稿のハッシュタグ構造〉
Profile

経営学部
吉見憲二
- 専門分野 情報社会学、経営情報学
- 担当授業 情報戦略、情報産業、情報コミュニケーション技術、経営専門演習、基礎演習など
- 研究に関連するコンテンツ
- ・リサーチマップ
- ・情報学研究データリポジトリ


